Die erweiterten Fähigkeiten von ChatGPT, wie zum Beispiel das Debuggen von Code, das Verfassen von Aufsätzen oder das Erzählen von Witzen, haben zu seiner enormen Beliebtheit geführt. Trotz seiner Fähigkeiten war seine Unterstützung bisher auf Text beschränkt - aber das wird sich ändern.
Am Dienstag präsentierte OpenAI GPT-4, ein großes multimodales Modell, das sowohl Text- als auch Bildinputs akzeptiert und Text ausgibt.
Außerdem: Wie man ChatGPT Quellen und Zitate bereitstellen lässt
Der Unterschied zwischen GPT-3.5 und GPT-4 wird bei informellen Gesprächen "subtil" sein. Das neue Modell wird jedoch in Bezug auf Zuverlässigkeit, Kreativität und sogar Intelligenz deutlich leistungsfähiger sein.
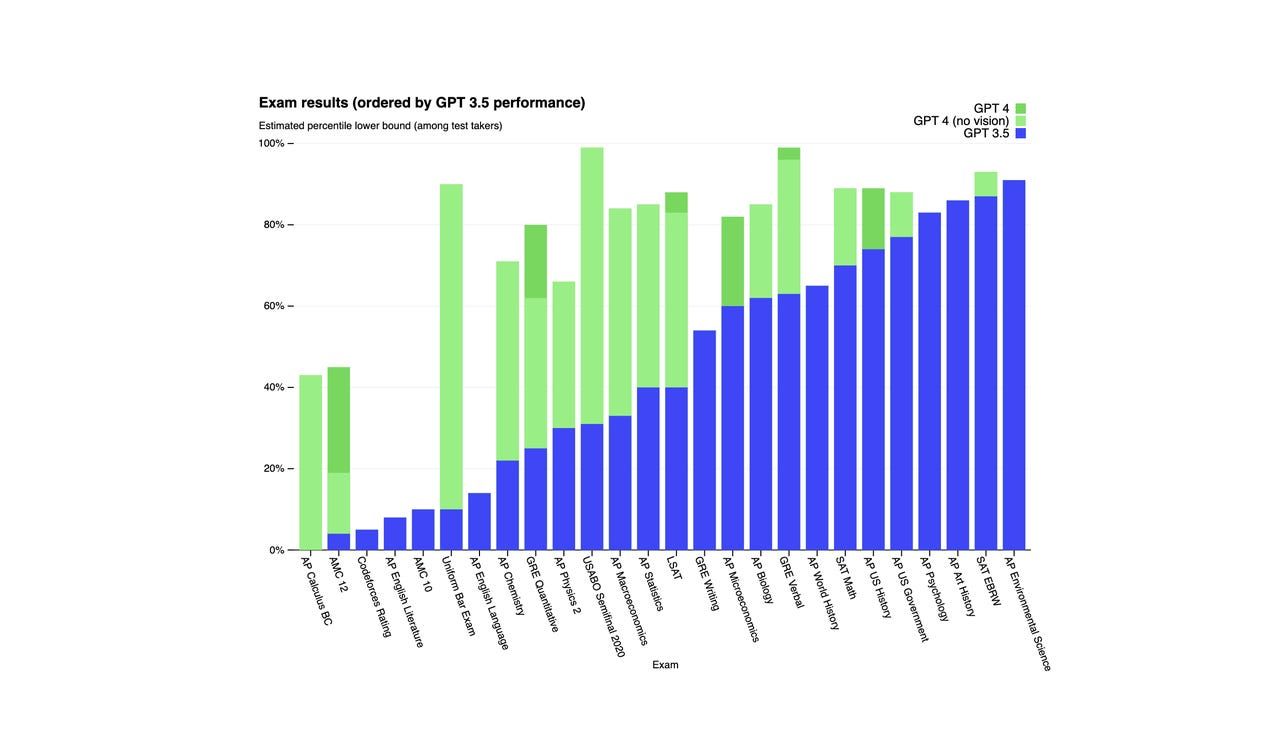
Gemäß OpenAI hat GPT-4 in einem simulierten Bar-Examen in den besten 10% abgeschnitten, während GPT-3.5 sich etwa in den untersten 10% platzierte. GPT-4 übertraf auch GPT-3.5 in einer Reihe von Benchmark-Tests, wie im Diagramm unten zu sehen ist.

Für den Kontext läuft ChatGPT auf einem Sprachmodell, das aus einem Modell der 3.5-Serie feinabgestimmt wurde und den Chatbot auf Textausgabe beschränkt.
Die Ankündigung von GPT-4 von OpenAI folgte letzte Woche einer Ansprache von Andreas Braun, CTO von Microsoft Deutschland, in der er sagte, dass GPT-4 bald kommen würde und die Möglichkeit zur Text-zu-Video-Generierung bieten würde.
Außerdem: Wie funktioniert ChatGPT?
"Wir werden nächste Woche GPT-4 vorstellen; dort werden wir multimodale Modelle haben, die völlig unterschiedliche Möglichkeiten bieten -- zum Beispiel Videos," sagte Braun laut Heise, einer deutschen Nachrichtenquelle, bei der Veranstaltung.
Trotz der Multimodalität von GPT-4 waren die Behauptungen über einen Text-zu-Video-Generator etwas ungenau. Das Modell kann noch keine Videos produzieren, aber es kann visuelle Eingaben verarbeiten, was eine bedeutende Veränderung gegenüber dem vorherigen Modell darstellt.
Eines der Beispiele, die OpenAI bereitgestellt hat, um diese Funktion zu präsentieren, zeigt, wie ChatGPT ein Bild scannt, um herauszufinden, was an dem Foto lustig ist, basierend auf der Eingabe des Benutzers.
Weitere Beispiele umfassen das Hochladen eines Bildes eines Diagramms und die Aufforderung an GPT-4, Berechnungen daraus durchzuführen, oder das Hochladen eines Arbeitsblatts und die Aufforderung, die Fragen zu lösen.
Außerdem: 5 Möglichkeiten, wie ChatGPT Ihnen bei der Erstellung eines Aufsatzes helfen kann
OpenAI gibt bekannt, dass es die Texteingabefähigkeit von GPT-4 über ChatGPT und seine API über eine Warteliste freigeben wird. Sie müssen noch etwas länger auf die Funktion zur Bilderkennung warten, da OpenAI mit einem einzigen Partner zusammenarbeitet, um diese Funktion zu starten.
Wenn Sie enttäuscht darüber sind, dass es keinen Text-zu-Video-Generator gibt, keine Sorge, es handelt sich nicht um ein völlig neues Konzept. Tech-Giganten wie Meta und Google arbeiten bereits an Modellen. Meta hat Make-A-Video und Google hat Imagen Video, die beide KI nutzen, um Video aus Benutzereingaben zu generieren.